为什么「身体」很重要?
2023 年起,「具身智能」站到了聚光灯下:谷歌与柏林工大推出多模态具身视觉语言模型 PaLM-E,英伟达发布具身 AI 系统 VIMA,马斯克展示能流畅行走的人形机器人 Tesla Bot,北京等地把具身智能列为重点方向,学界也密集举办相关论坛与讲习班。
我们习惯把「智能」等同于「大脑」——会下棋、会写诗、会做题。但现实中,让机器像一岁孩子那样看、走、拿东西,至今仍是难题。这背后有一个根本问题:智能是否必须依赖「身体」与「环境」的互动?当 AI 从「离身」走向「具身」,又会带来哪些机遇与挑战?下面就从「什么是具身智能」说起,再看到它如何落地、面临什么瓶颈。
一、智能不只在「脑」:什么是具身智能?
我们一提到智能,总会想到大脑。大脑当然重要,但身体的结构、动作和感觉,同样在塑造智能。 具身智能,简单说就是「带着身体的智能」:身体本身的运动和与环境的接触,会反过来影响大脑的发育与认知; 反过来,大脑也可以把意图交给身体去执行。
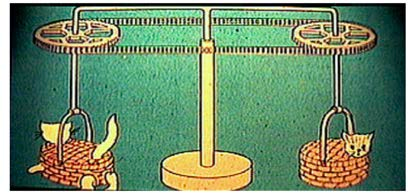
有两个经典例子。海鞘在找到满意的栖息地后会永久定居,不再需要移动,于是会「吃掉」自己的大脑——没有身体与环境的互动需求,脑的价值就大打折扣。「小猫旋转木马」实验更直接:两只小猫视觉输入相同,一只可以主动走,另一只被装置带着被动走;结果只有主动走的那只发育出正常的感知–运动能力,被动的那只出现明显障碍。主动的身体活动,是感知与运动系统正常发展的前提。
今天很多 AI 擅长看图、对话、下棋,却不太会「动手动脚」、在真实世界里完成任务。一个核心原因在于:我们更多在练「感知和推理」, 没有把「身体—环境」的互动当作智能的一部分。强调这一点的,叫具身智能; 忽略身体、只把身体当「执行器」的,常被称作离身智能。二者不是非此即彼,而是互补的两条路线。
二、从哲学到机器人:具身智能的来龙去脉
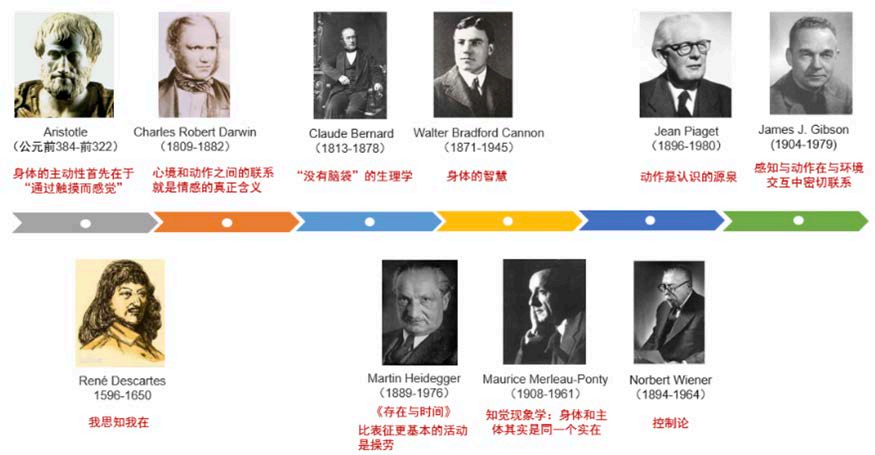
具身智能「想法很老,工程很新」。亚里士多德、达尔文、梅洛–庞蒂、皮亚杰、吉布森等人在哲学、生理、心理与认知科学里,早就强调感知、身体和环境的不可分割。 一个被广泛接受的观点是:认知并不只发生在「脑」里,而是来自感知–动作–环境的连续回路;很难严格区分「感知在哪结束、认知在哪开始」。
人工智能这边,早期以符号主义为主:用规则和逻辑在「脑」里处理抽象表示,身体只负责执行。后来联结主义(神经网络、深度学习)崛起, 在数据与算力加持下,在图像、语言等领域大放异彩,但和真实物理世界的「动手」仍然脱节。 于是有了莫拉维克悖论的经典表述:让电脑像成人一样下棋相对容易,让电脑具备一岁孩子的感知与行动能力却极其困难。 布鲁克斯等人因此强调:「智能需要一个身体」,智能是具身的、且与环境紧密相关。这推动了行为主义和具身人工智能的发展。
所以,离身智能(偏重「脑」:表示、推理、大数据)与具身智能(偏重「身体—环境」交互)目标一致,但侧重点不同;二者相互补充、协同发展,才能共同走向更通用的智能。接下来看具身智能在具体任务里是怎么体现的。
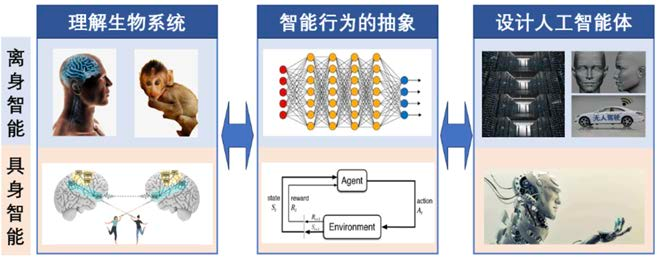
三、具身智能在做什么?四类典型任务
具身智能是硬件、软件与算法一体的系统智能,不能单靠「一个算法」实现。判断一个系统是否具身,不仅要看它有多「聪明」,更要看有多少智能来自身体与环境的交互。典型地可以分成四类:
(1)用身体与环境的交互实现「发现」(具身感知)——若一辆车上的视觉程序能检测所有目标,但程序完全来自大数据训练,车体只是载体,具身性不强。 反之,若一只机械鼠用触须主动探洞、靠触碰发现目标,这就是典型的具身感知。
(2)用身体与环境的交互实现「学习」(具身学习)——传统学习依赖事先准备好的数据和标签。若机器人通过动手操作(摸、推、抓)获得触觉、视觉等多模态信息, 并据此改进对物体的理解,那就是具身学习。
(3)用身体与环境的交互实现「控制」(形态智能)——很多展示型机器人的动作是事先编好的;而被动行走机器人能在小坡上无动力稳定行走, 软体机器人则利用自身形态与材料承担一部分「计算」,从而简化控制器。这类形态计算、形态控制是具身智能的重要形式。
(4)用身体与环境的交互实现「优化」(形态优化)——不只在控制上做文章,还可以优化身体结构本身(离线甚至在线),使机器人更适应任务与环境,相当于给机器以「发育、进化」的可能;结构优化往往需要与控制设计协同进行。
这四类任务背后,都离不开「形态、行为、感知、学习」四个模块的协同。下一节就看看身体是如何参与「思考」的。

四、身体如何参与「思考」:形态、行为、感知与学习
从技术上看,具身智能可以拆成形态、行为、感知、学习四个模块,它们彼此紧密耦合。形态计算是让「身体」承担一部分本要交给「脑」的活;主动感知是通过移动、改变姿态或操作环境,获得更好的观测条件;形态控制是利用身体的结构约束简化控制设计;形态优化是用学习与进化方法搜索更好的身体形态与参数。
这些模块必须一起工作:感知、语言、动作处于不同「空间」,对齐本身就难;任一环节出问题,整个具身系统都可能失效,所以具身智能本质上是高度集成的系统问题。这也带来了它的优点、缺点与难点。
五、优点、缺点与难点:主动、安全与集成
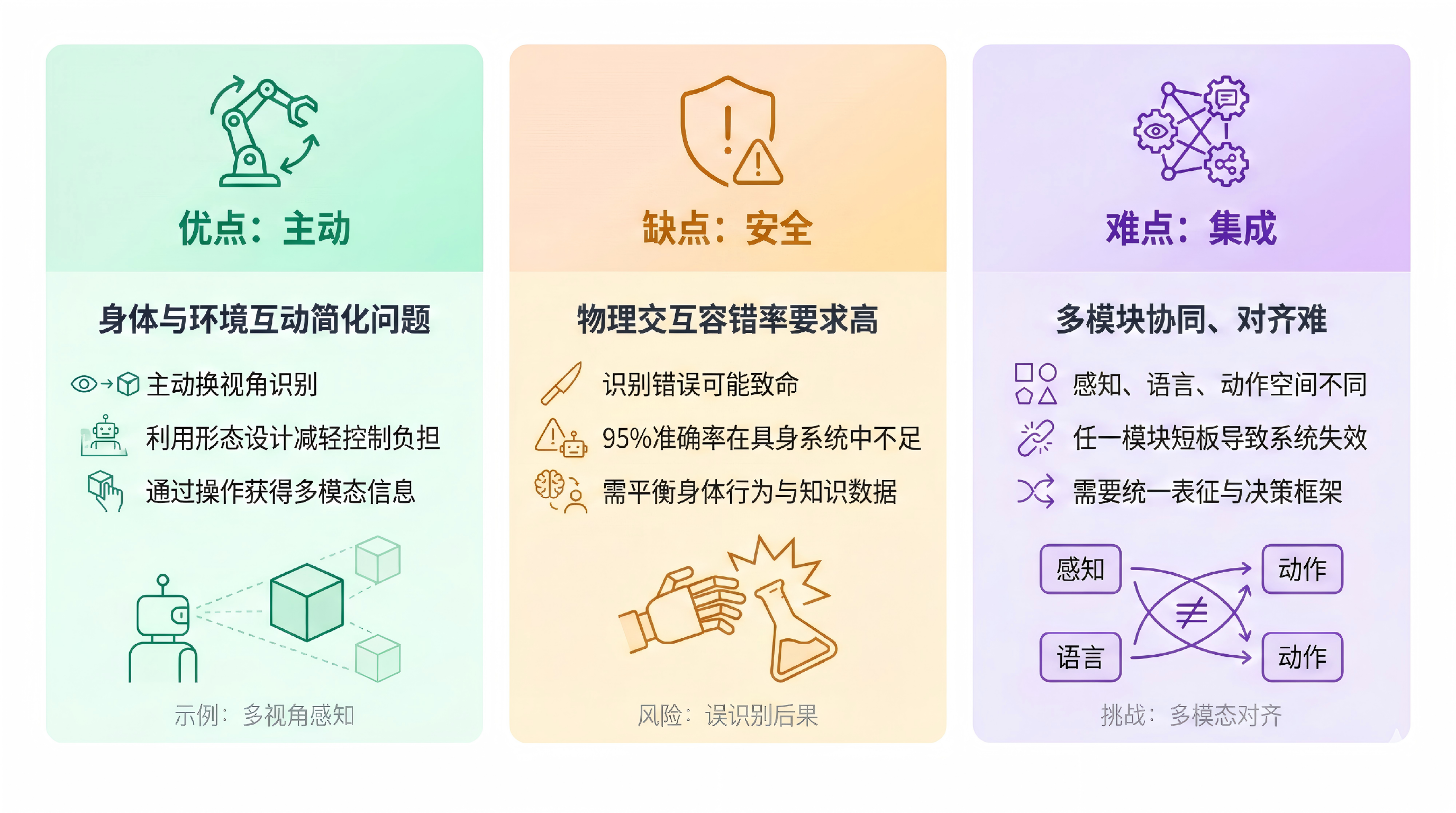
具身智能的特点可以概括为三句话:优点在「主动」,缺点在「安全」,难点在「集成」。
优点:主动。一旦引入「身体–环境」交互,很多问题可以变简单。例如:背面看不清的物体,不必只靠算法硬算,可以动起来换视角再识别; 好的形态设计(如飞机气动布局)能利用环境,减轻控制器的负担。
缺点:安全。与物理世界直接交互,容错率要求更高。在纯识别任务里 95% 准确率或许能上线;在具身系统里,若把「刀」认成「梳子」,可能带来致命后果。 此外,若只强调身体与行为、忽视知识与数据,容易走向「四肢发达、头脑简单」,这也是需要警惕的。
难点:集成。智能来自环境、身体与「脑」的协同,需要把感知、语言、动作对齐到同一套表征与决策中,而它们天然处于不同空间。 同时,具身系统是整体,感知、规划、控制任一模块的短板都可能导致系统失败,因此集成与鲁棒性是核心难点。这些难点也体现在当前的前沿与挑战里。
六、前沿与挑战:多模态、仿真到现实、形态与应用
把上述优点与难点放到当前研究里看,有几个突出的前沿与挑战。具身多模态感知:目前「多模态」多指视觉+语言等,仍偏离身。真正的具身多模态还包括触觉——触觉是身体与物理世界交互的桥梁, 对安全、稳定与柔顺控制至关重要,但触觉传感器与算法仍明显落后于视觉与听觉,是重要瓶颈。
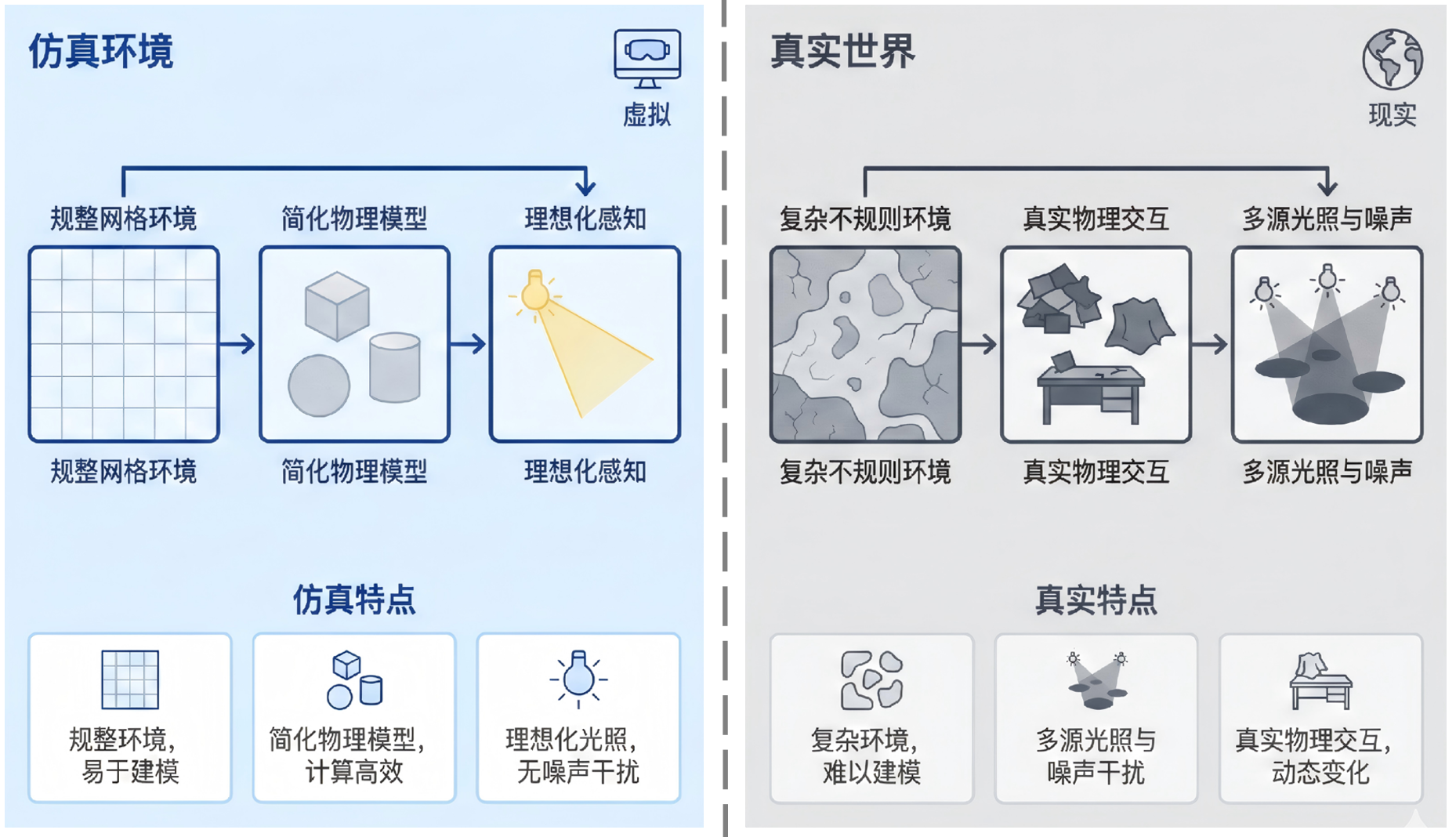
仿真与现实的鸿沟(Sim2Real):在仿真里训练的具身智能体,迁移到真实世界常会性能大跌。当前思路包括:增强仿真多样性(如域随机化), 以及缩小仿真与真实在感知、动作空间上的差异。
形态未得到足够重视:很多导航、操作任务在仿真里只定义简单动作空间,未充分考虑智能体形态;形态计算、形态控制与形态优化尚未成为主流方向。
应用驱动:具身智能的再次升温离不开产业需求。大模型、AIGC 等被引入具身领域并带来新思路,但核心挑战——如 Sim2Real、多模态对齐、形态–控制协同——并未被根本解决。 以机器人为代表的具身智能体,需要在真实生活与生产中落地,并在应用驱动下凝练任务与方案,才可持续发展。
要点回顾
- 身体与环境的主动交互是智能的重要组成部分——海鞘与小猫实验表明,没有身体活动与环境的互动,感知与认知无法正常发展。
- 离身智能与具身智能目标一致、侧重不同——离身偏重表示与推理,具身偏重身体–环境交互;二者应互补协同。
- 具身智能通过四类任务体现:具身感知、具身学习、形态计算与形态控制、形态优化。
- 具身智能的优点在「主动」,缺点在「安全」,难点在「集成」——需在发挥身体与环境交互优势的同时,高度重视安全与多模块协同。
- 触觉、Sim2Real、形态设计与应用落地仍是当前主要瓶颈;大模型等新技术带来机会,但核心科学问题仍待突破。
小结
智能不仅来自「脑」,也来自身体与环境的持续互动。从哲学与认知科学到符号主义、联结主义,再到行为主义与具身人工智能,离身与具身两条路线正在走向融合。儿童发展顺序是「先动后想、先身体后符号」,而 AI 的发展长期是「先符号、先数据」——具身智能提示我们:从微小能力出发,在与环境的交互中逐步「发育」,可能是通向更通用智能的一条路径。未来,从数据中学习语义、利用符号推理、再通过身体与物理世界交互,三者结合,才有望实现更完整的智能;以机器人为载体的具身智能,也将在实际应用中不断定义新任务、新标准。